哈希算法
先前讲到的哈希扩容本质上并不能减少哈希冲突的发生,只是能保证在发生哈希冲冲突的情况下能够继续使用哈希表。优化哈希算法从根源上降低哈希冲突的发生概率,是目前已知最有效的方法。 以链式存储实现的哈希为例,理想情况下键值对均匀分布在各个桶中,达到最佳查询效率;最差情况下所有键值对都存储到同一个桶中,时间复杂度退化至O(n)。每个哈希元素在“桶”的位置是由哈希函数决定的,优化哈希函数使无规律分布的key均匀分布在桶中,从而降低哈希冲突的概率,实现哈希表的高效存储和安全性。
常见的哈希算法
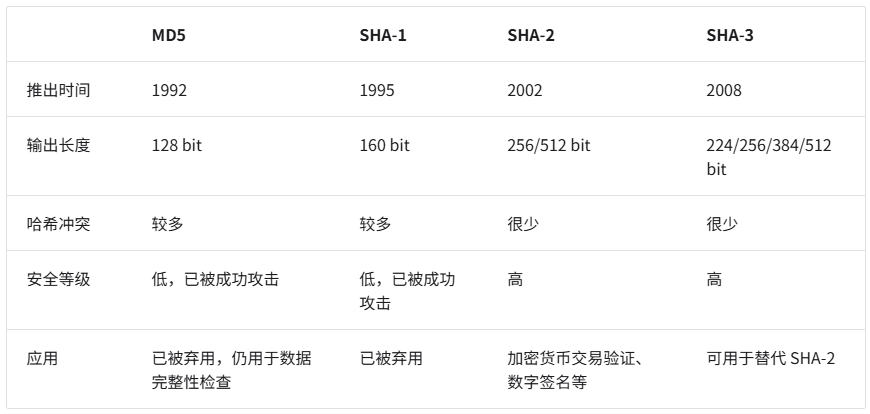
一些标准哈希算法,例如 MD5、SHA-1、SHA-2 和 SHA-3 等。它们可以将任意长度的输入数据映射到恒定长度的哈希值。哈希算法的高效性和安全性一直都是优化哈希算法的关键。下面是已知标准哈希算法的具体信息:
简单哈希算法的设计
一个标准且完善的哈希算法的设计通常要考虑的因素是相当复杂的。但对于一下要求不高的场景,可以设计一些简单的哈希算法来满足要求。
- 加法哈希:对输入的每个字符的 ASCII 码进行相加,将得到的总和作为哈希值。
- 乘法哈希:利用乘法的不相关性,每轮乘以一个常数,将各个字符的 ASCII 码累积到哈希值中。
- 异或哈希:将输入数据的每个元素通过异或操作累积到一个哈希值中。
- 旋转哈希:将每个字符的 ASCII 码累积到一个哈希值中,每次累积之前都会对哈希值进行旋转操作
/* 加法哈希 */
fn add_hash(key: &str) -> i32 {
let mut hash = 0_i64;
const MODULUS: i64 = 1000000007;
for c in key.chars() {
hash = (hash + c as i64) % MODULUS;
}
hash as i32
}
/* 乘法哈希 */
fn mul_hash(key: &str) -> i32 {
let mut hash = 0_i64;
const MODULUS: i64 = 1000000007;
for c in key.chars() {
hash = (31 * hash + c as i64) % MODULUS;
}
hash as i32
}
/* 异或哈希 */
fn xor_hash(key: &str) -> i32 {
let mut hash = 0_i64;
const MODULUS: i64 = 1000000007;
for c in key.chars() {
hash ^= c as i64;
}
(hash & MODULUS) as i32
}
/* 旋转哈希 */
fn rot_hash(key: &str) -> i32 {
let mut hash = 0_i64;
const MODULUS: i64 = 1000000007;
for c in key.chars() {
hash = ((hash << 4) ^ (hash >> 28) ^ c as i64) % MODULUS;
}
hash as i32
}以上四个简单哈希算法的设计都存在一个共同点:最终的哈希值都要对一个大质数取模运算。为什么是一个大质数?使用大质数作为模数,可以最大化地保证哈希值的均匀分布。质数仅有1和它本身两个公约数,这样并不能清晰直观地展示出质数相较于合数作为模数的优势。以下面例子来展示其优势:
以合数9为模数,它可以被 3 整除,那么所有可以被 3 整除的
key都会被映射到 0、3、6 这三个哈希值。modulus = 9; key={0,3,6,9,12,15,18,21,24,27,30...} hash = {0,3,6,0,3,6,0,3,6}如果输入
key恰好满足这种等差数列的数据分布,那么哈希值就会出现聚堆,从而加重哈希冲突。现在,假设将modulus替换为质数 13 ,由于key和modulus之间不存在公约数,因此输出的哈希值的均匀性会明显提升。如果将模数从9替换为13
modulus = 13; key={0,3,6,9,12,15,18,21,24,27,30...} hash = {0,3,6,9,12,2,5,8,11...}
TIP
倘若key能以均匀随机的规律分布,那么无论使用合数还是质数,都能保证hash分布的均匀性。
但总而言之,选取模数总倾向于大质数,越大越好。
数据结构的哈希值
在许多编程语言中,只有不可变对象才可作为哈希表的 key 。假如我们将列表(动态数组)作为 key ,当列表的内容发生变化时,它的哈希值也随之改变,我们就无法在哈希表中查询到原先的 value 了。
虽然自定义对象(比如链表节点)的成员变量是可变的,但它是可哈希的。这是因为对象的哈希值通常是基于内存地址生成的,即使对象的内容发生了变化,但它的内存地址不变,哈希值仍然是不变的。
哈希表的 key 可以是整数、小数或字符串等数据类型。编程语言通常会为这些数据类型提供内置的哈希算法,用于计算哈希表中的桶索引。
- 整数和布尔量的哈希值就是其本身。
- 浮点数和字符串的哈希值计算较为复杂,有兴趣的读者请自行学习。
- 元组的哈希值是对其中每一个元素进行哈希,然后将这些哈希值组合起来,得到单一的哈希值。
- 对象的哈希值基于其内存地址生成。通过重写对象的哈希方法,可实现基于内容生成哈希值。
use std::collections::hash_map::DefaultHasher;
use std::hash::{Hash, Hasher};
let num = 3;
let mut num_hasher = DefaultHasher::new();
num.hash(&mut num_hasher);
let hash_num = num_hasher.finish();
// 整数 3 的哈希值为 568126464209439262
let bol = true;
let mut bol_hasher = DefaultHasher::new();
bol.hash(&mut bol_hasher);
let hash_bol = bol_hasher.finish();
// 布尔量 true 的哈希值为 4952851536318644461
let dec: f32 = 3.14159;
let mut dec_hasher = DefaultHasher::new();
dec.to_bits().hash(&mut dec_hasher);
let hash_dec = dec_hasher.finish();
// 小数 3.14159 的哈希值为 2566941990314602357
let str = "Hello 算法";
let mut str_hasher = DefaultHasher::new();
str.hash(&mut str_hasher);
let hash_str = str_hasher.finish();
// 字符串“Hello 算法”的哈希值为 16092673739211250988
let arr = (&12836, &"小哈");
let mut tup_hasher = DefaultHasher::new();
arr.hash(&mut tup_hasher);
let hash_tup = tup_hasher.finish();
// 元组 (12836, "小哈") 的哈希值为 1885128010422702749
let node = ListNode::new(42);
let mut hasher = DefaultHasher::new();
node.borrow().val.hash(&mut hasher);
let hash = hasher.finish();
// 节点对象 RefCell { value: ListNode { val: 42, next: None } }基于内容值 的哈希值为15387811073369036852