哈希冲突与扩容
以key取模运算来映射index为例,很容易发现存在哈希冲突的情况。
12836 % 100 = 36
20336 % 100 = 36如何避免哈希冲突?不难发现在key构成的输入空间趋近于无限的前提下,哈希表的容量Capcity越大,发生哈希冲突的概率越低。因此扩容哈希表可以一定程度有效避免哈希冲突。
哈希扩容需要将原来的桶迁移到新的哈希表中,需要重新计算原本的key在哈希表中映射的位置,非常的耗时。通常情况下,编程语言都会为哈希表预留充足的空间防止频繁扩容造成性能损耗。存在一个衡量标准:负载因子,表示哈希冲突程度,该值为 哈希表元素数量和容量的比值,通常为0.75,超出后自动扩容2倍。
解决哈希冲突
1.链式地址
哈希表扩容某种意义上是牺牲一定性能的暂时的"权宜之计"。想更好地解决哈希冲突,优化哈希表的数据结构以在冲突情况下可以正常使用作为第一策略,必要时再进行扩容操作。以链表原理将发生冲突的hash(key)的元素链式存储(实现使用动态数组vec)。
优化hash的实现结构以更优地解决哈希冲的问题,本质上是将hash表看作一个大的“桶”,里面又存在若干个小“桶”,"桶是动态vec",每个小桶用于存储 经由“哈希函数”处理后发生的冲突的key,value组合,即把发生冲突的元素存在一起,再匹配key相等的实现冲突情况下能够正确访问。
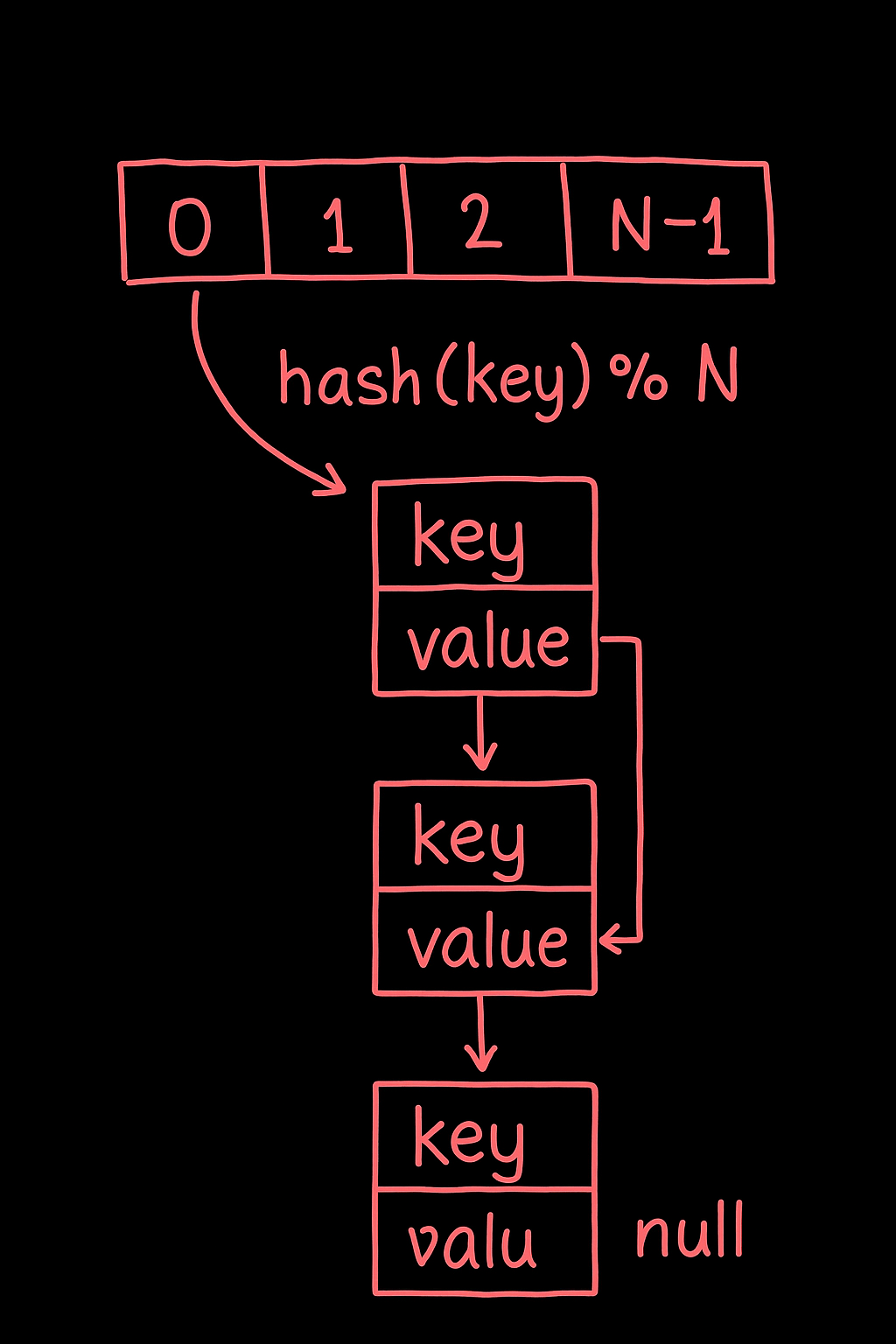
以初始容量4,负载因子2/3,扩容倍率2为初始化参数,实现如下:
rust
#[derive(Debug,PartialEq,Clone)]
pub struct Pair{
key:i32,
val:String
}
#[derive(Debug)]
pub struct LinkListHash{
size:usize,
capacity:usize,
load_rate:f32,
extend_ratio:i32,
bucket:Vec<Vec<Pair>>
}
impl LinkListHash {
pub fn new() -> LinkListHash{
Self{
size:0,
capacity:4,
load_rate:2.0/3.0,
extend_ratio: 2,
bucket: vec![vec![];4],
}
}
//哈希函数
fn hasn_func(&self,key:i32)->usize{
key as usize % self.capacity
}
//判断是否需要扩容
fn is_extend(&self) -> bool{
(self.size / self.capacity) as f32 >= self.load_rate
}
//扩容
pub fn extend_content(&mut self){
//先暂存原本的bucket
let old = self.bucket.clone();
self.capacity *= self.extend_ratio as usize;
self.bucket = vec![vec![];self.capacity];
//扩容后要对“小桶”内的元素重新设置位置,否则key % capacity(capacity翻倍了)无法匹配之前的位置导致无法访问
for bucket in old.iter(){
for pair in bucket {
let index = self.hasn_func(pair.key);
self.bucket[index].push(pair.clone())
}
}
}
//添加元素
pub fn add(&mut self, key:i32, value:&str) {
let index = self.hasn_func(key);
//判断是否超载,若超载则扩容
if self.is_extend(){
self.extend_content()
}
//判断是否已经存在相同的key,若存在则替换,否则return
for pair in self.bucket[index].iter_mut() {
if pair.key == key {
pair.val = value.to_string();
}
return;
}
//不存在该key,则添加到对应小桶的尾部
self.bucket[index].push(
Pair{
key,
val:value.to_string()
}
);
self.size += 1;
}
//获取元素
pub fn get(&self,key:i32)->Option<&Pair>{
let index = self.hasn_func(key);
for pair in self.bucket[index].iter() {
if pair.key == key{
return Some(pair)
}
}
None
}
//删除元素
pub fn remove(&mut self,key:i32) -> Option<Pair>{
let index = self.hasn_func(key);
for (i,pair) in self.bucket[index].iter_mut().enumerate() {
if pair.key == key {
let removed = self.bucket[index].remove(i);
self.size -= 1;
return Some(removed)
}
}
None
}
}
#[cfg(test)]
mod test{
use super::*;
#[test]
//测试创建、新增、删除
fn it_works(){
let mut ls = LinkListHash::new();
ls.add(12,"lily");
let removed = ls.remove(12);
assert_eq!(removed,Some(Pair{key:12,val:"lily".to_string()}));
assert_eq!(ls.bucket,vec![vec![];4])
}
#[test]
//测试添加相同key的元素、获取元素
fn repeat(){
let mut ls = LinkListHash::new();
ls.add(12,"lily");
ls.add(12,"jack");
assert_eq!(ls.get(12),Some(&Pair{key:12,val:"jack".to_string()}))
}
#[test]
//测试扩容
fn extend(){
let mut ls = LinkListHash::new();
ls.add(12,"lily");
ls.extend_content();
assert_eq!(1,ls.size);
assert_eq!(8,ls.capacity);
assert_eq!(ls.get(12),Some(&Pair{key:12,val:"lily".to_string()}));
}
}2.开放寻址
...